Thanks so much for looking at the docs for my resume site. I've compiled information about how the site works, mostly to showcase some of the technologies I've used to make all of this work. Enjoy!
Technologies
The site utilizes a number of technologies to operate.
- Flask is at the top. Flask is a Python library that provides a very easy way to serve web content, and that's used for everything here.
- Python is my programming language of choice, and the language this site runs on. At the moment, version 3.12.
- Kubernetes is a container orchestration engine. It provides all the components required to effortlessly deploy new versions of this site through code, as well as handle capacity and networking changes.
- Docker, of course. All of the containers for Kubernetes run on Docker, so Docker has to be included in the list.
- Ubuntu is my operating system of choice for container workloads. Generally, I use RHEL/Rocky for traditional things, but container workloads specifically seem to run more reliability on Ubuntu.
- VMware is the hypervisor that I run all of the virtual machines on in my home datacenter. There are more cost effective options, but I find VMware to be a more powerful and effective tool than the others.
- Supermicro hardware provides all of the compute, memory, and storage resources needed to run my workloads.
All of the code, both for Kubernetes and Python, is located on GitHub.
Python
Flask and Python power all of the logic for the site. Currently it uses Flask 3.0.0 and Python 3.12. Waitress 2.1.2 is also in use as a WSGI server, to provide a more performant and secure web protocol layer than what Flask comes with.
- At the root level of the application, we have a few listeners set up.
-
/ - The root page for the site. From here, Flask inserts some variables into a static HTML template, and serves that completed page to the browser. There's also a method in place,
utils.auto_link(), that parses the generated HTML and creates hyperlinks based on the first occurrence of a list of keywords. This way, for example, people that may not be familiar with Mulesoft can have a link to more information about it. - /about - This page, of course. Similarly to the root page, Flask just inserts some variables into a static template, and serves that page to the browser. There's no automatic link creation here, though, as that should all be intentional on this page.
- /pdf - A page that uses LaTeX to serve a PDF with minimal design elements that is better formatted for ingestion by HR systems.
- /pdf-old - An older version of the /pdf endpoint that makes a PDF of the full site, styling included.
- /ping - I like to include /ping endpoints in my applications. These provide an easy way to get the operational status of the underlying web services, before you start worrying about the actual functionality of those services. If we hit /ping, and get "pong" back, we know every bit of the architecture up to and including Flask itself is working as expected. Kubernetes also uses this to know of a container is done starting up.
- /health - I also like to include a more detailed 'health check' endpoint. In this case, it isn't particularly valuable, we could probably just monitor the root page and have the same effect. If there was a database or some other sort of dependency, this function would make a simple call to that to ensure everything works. Kubernetes watches this to make sure a container is healthy.
Kubernetes
Kubernetes (k8s) is what's used to orchestrate the containers that run the site.
I also use Rancher as a k8s orchestration engine. Aside from the convenient web UI, I find that it provides a nice, straightforward way to add and remove k8s cluster nodes.
Rancher also automatically provisions containers (pods), load balancers (ingresses), and any other k8s components automatically from code. You can find code for this in the /deploy folder inside the git repository.
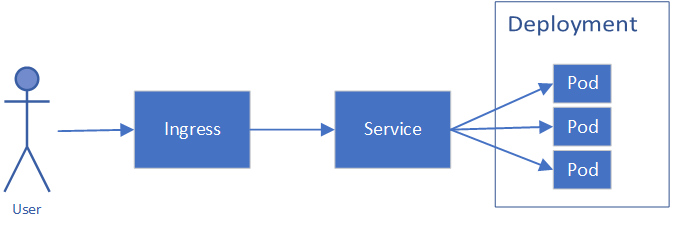
Active Kubernetes elements for the site are:
- Deployment - This defines the functional containers (pods) that run the site. It includes definitions for the container image, replica count, health check, environment variables, and more.
- Service - This is, essentially a way to target all of the pods in a deployment, by label. With a service, you can send traffic from another service, or an ingress, to any active pod behind that service, without having to know individual pod names or IPs.
- Ingress - Ingresses are the way to link an externally accessible target, like a node port, to a service. Here, you define listening ports, protocols, and certificates that should be used.
There is also a similar copy of this for dev.nickwork.net, which is the development version of this site.
Linux
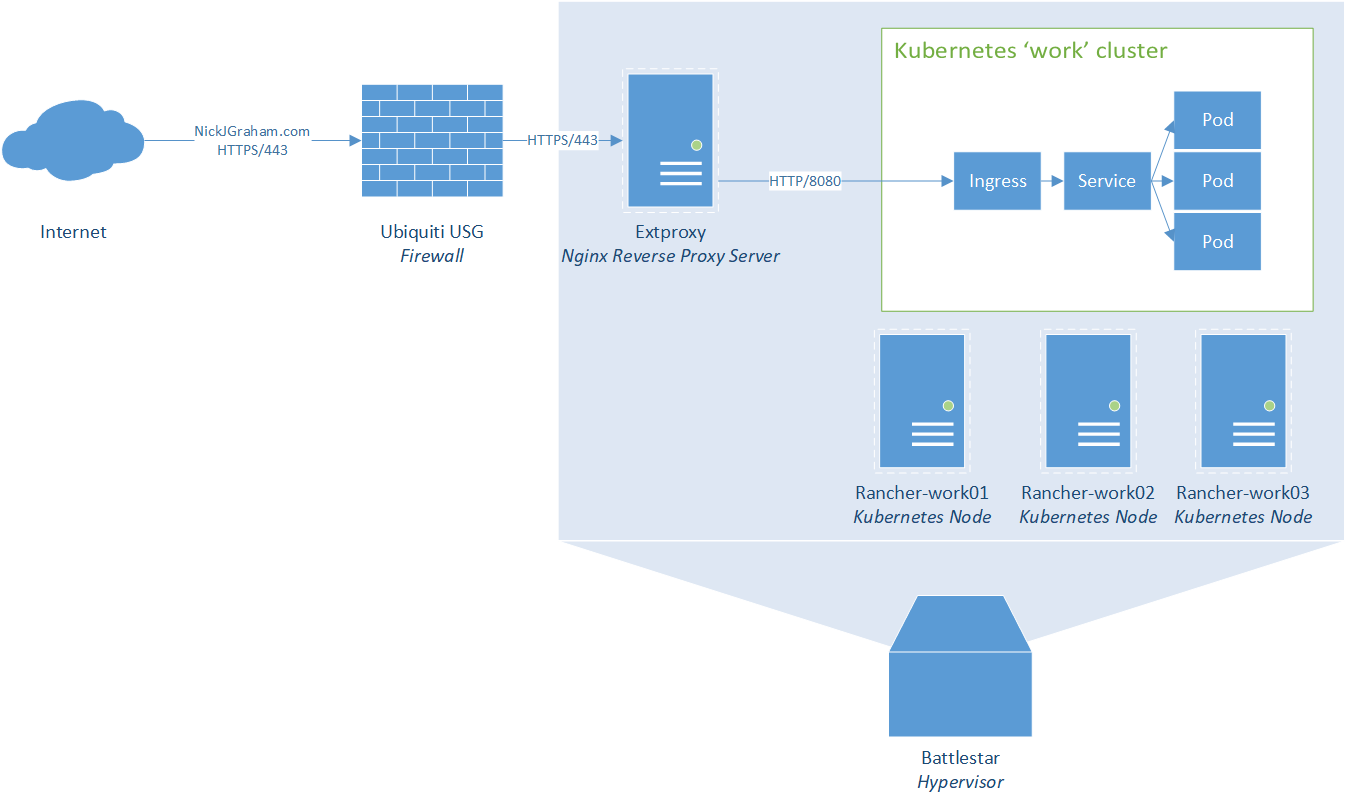
The Linux servers for the system run Ubuntu 22.04 LTS. They also run Docker 20.10. There are 6 servers in total, providing 2 Kubernetes clusters.
- Management Cluster - Runs Rancher
- rancher-man01
- rancher-man02
- rancher-man03
- Workload Cluster - Runs everything else
- rancher-work01
- rancher-work02
- rancher-work03
This is not an ideal architecture. Ideally, we would have 6 or more servers per cluster, where 3 run the etcd/control plane roles, and the remaining 3 (or more) run the worker role. However, considering that each of these servers has 4 CPU, and 8GB of memory, that is a bit too expensive for my home lab. Because of that, all of the servers run all roles.
VMware
VMware is another critical component of the system, but the architecture is not particularly complex.
There is a single VMware host, battlestar, that runs all of my virtual machines, including others that are not involved with this project. It is managed by a vCenter server, but that it is about the extent of its complexity.
Hardware
Services run off of a single 4U Supermicro server, with these specs:
- Motherboard - Supermicro X9DRi-LN4+
- CPU - 2x Intel E5-2697 v2, total of 24 cores (48 with HT) @ 2.70 GHz
- Memory - 352 GB
- Storage:
- 2x 1TB SSD - RAID 1
- 2x 2TB SSD - RAID 1
- 16x 4TB 7200 RPM HDD - RAID 10
- Network - 4x Intel 1 Gbps
This server lives in a small half-height rack with redundant power. It's connected to a Ubiquiti USW-Flex-Mini switch via 1 ethernet cable, because there's no other network redundancy in that location. It's also connected to a Dell Powervault 124T tape library via SAS.

Traffic Flow
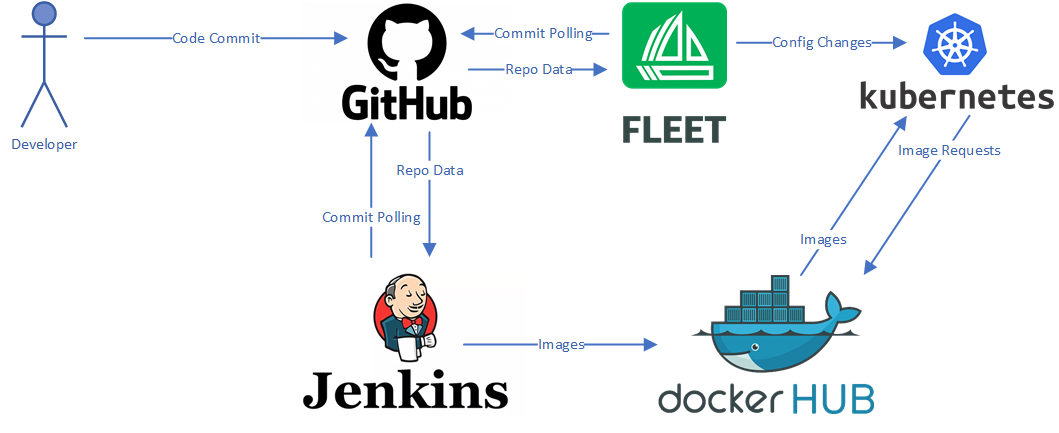
What would a documentation page be without a traffic flow diagram?
Continuous Integration / Continuous Delivery
Changes to this site are built and deployed automatically using a few different tools.
- GitHub - Hosts the code.
- Jenkins - Builds and pushes container images.
- DockerHub - Hosts container images.
- Fleet - An orchestration engine that runs in Kubernetes, Fleet watches Git for config changes and deploys changes automatically.
The process looks a little something like this:
- Code changes are pushed up to GitHub.
- Jenkins detects changes in the main Git branch and starts a build.
- Fleet detects changes in Git as well, and updates Kubernetes settings.
- Most changes will be applied immediately, but if the specified image is changed, and is not yet available, perhaps to update the version to that of the current build, Kubernetes will just wait idly and keep retrying until the image is ready.
- Jenkins builds a container locally and performs linting against the Python code inside that container using flake8.
- Jenkins builds the container again, and pushes it up to DockerHub with the appropriate tags (build #, and 'latest').
- If Kubernetes has been waiting from step 3, it will now deploy the applicable version of the image.
- The change is now live, and all it took was a code push.
Running Locally
So, how do you run this site yourself? The answer to that depends on what you have available. You can either run it in a container, or directly on a Linux system with Python.
Docker
Running with Docker is surprisingly straightforward.
On your Docker host, run the following command:
docker run -p 8080 nicholasjgraham/nickjgraham.com
This will download the container image and run it. The container runs on port 8080, so the command includes an instruction to map that port to the container.
To browse, visit http://<your docker host>:8080. Easy!
Python
Running on Python requires a bit of extra setup. First, make sure you have Python 3.12.x installed. There's probably something in your package manager you can use, or you can compile from source here.
In order to run the /pdf endpoint you'll need the pdflatex utility. On Ubuntu you can get this by running:
sudo apt-get install -y texlive-latex-base texlive-fonts-recommended texlive-fonts-extra texlive-latex-extra
Then, you'll need to make sure you have git installed. You should install git using your package manager.
With those ready, you can run through the set up steps.
- Open a Bash or Powershell session and navigate to a free directory.
- Clone the git repository -
git clone https://github.com/nicholasjgraham/nickjgraham.com.git - Change to that new directory -
cd nickjgraham.com - Create the python virtual environment -
./py-init.shon Linux, or./py-init.ps1on Windows. - Change to the 'src' directory -
cd src - Start the service -
waitress-serve __init__:app
You should now be able to reach the app on http://localhost:8080!